Open sourcing Sweep Next-Edit v2 and our inference runtime
We’re open sourcing the next version of our autocomplete model — and the runtime that serves it.
Today we’re releasing two more pieces of our autocomplete stack:
- Sweep Next-Edit v2 — a 7B next-edit autocomplete model, the successor to the 1.5B model we open sourced earlier.
- Our TensorRT-LLM fork — the inference runtime we use to serve these models in production, at a P50 of 100ms end-to-end on our Qwen2.5 Coder fine-tune.
The model
Sweep Next-Edit v2 predicts your next code edit before you make it, just like v1 — but at 7B parameters it has more headroom for the harder, longer-range edits where the smaller model struggled.
Everything we wrote up about our training format and data still applies. The weights are on Hugging Face under a permissive license, so you can run it locally or build it into any editor — VSCode, Neovim, Emacs, and beyond.
Reinforcement learning rewards
Like v1, we finished training with on-policy RL. v2 adds three reward functions that target the failure modes we saw most often in production.
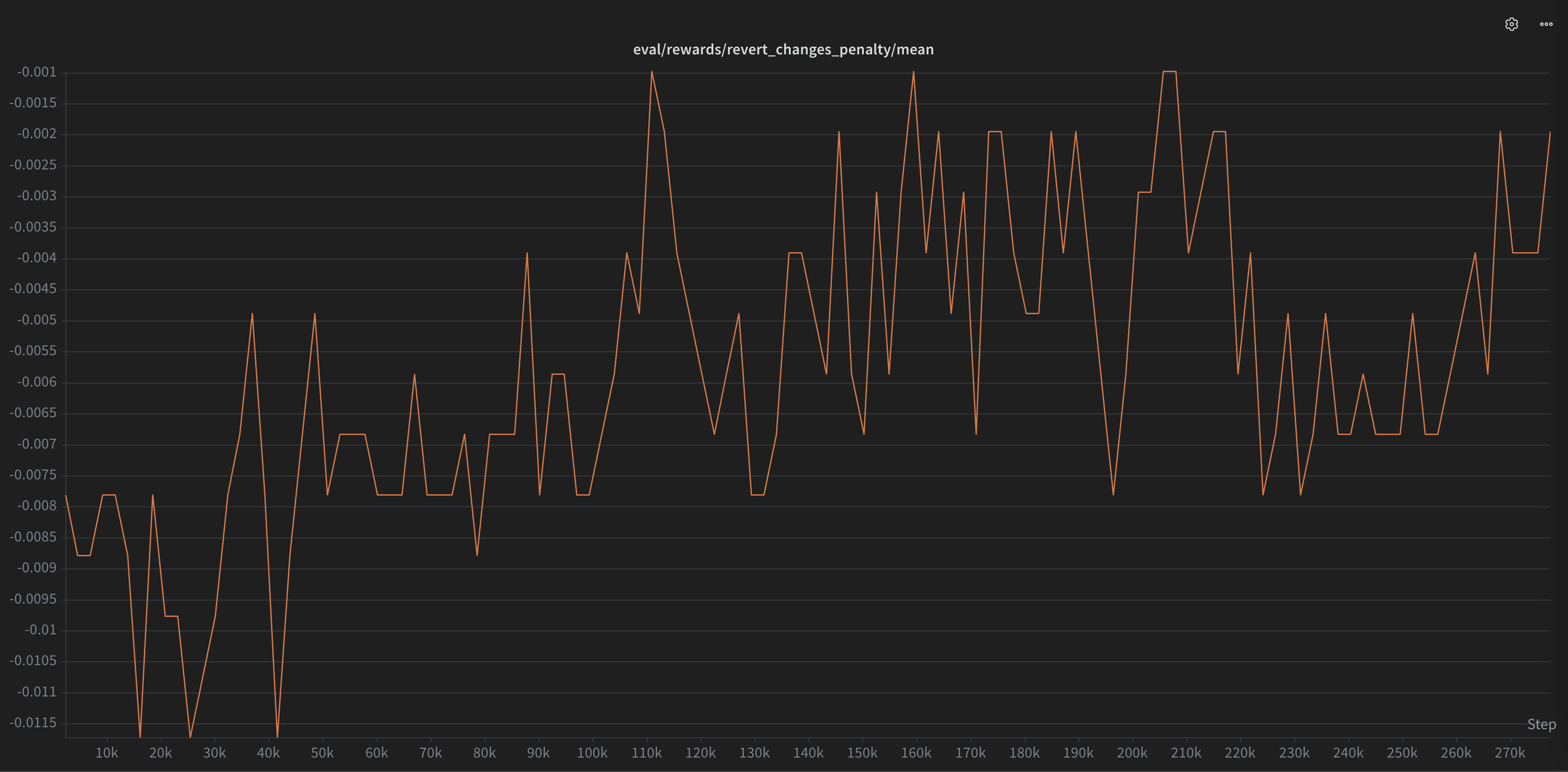
Don’t re-suggest reverted code
A suggestion the user already typed and then undid is almost always wrong. So we traverse the editor’s undo stack and check whether the model’s suggestion appears in it — if it does, we apply a penalty. This pushes the model away from “helpfully” re-introducing changes the developer just deleted.
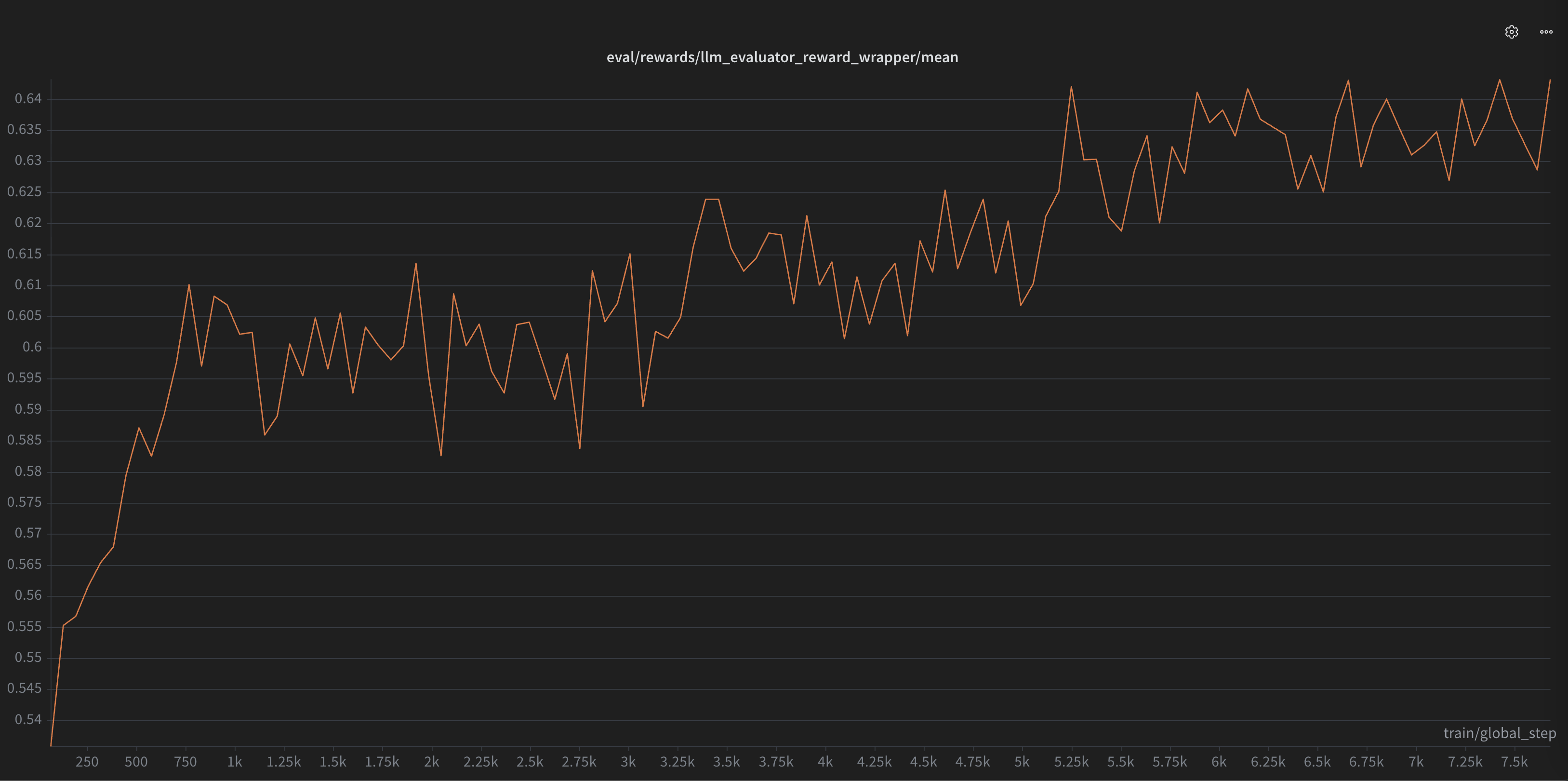
Ranking suggestions with an LLM judge
We use Claude Opus 4.5 as an LLM-as-a-judge to rank candidate completions from best to worst. Opus has far stronger long-context reasoning than a 7B model, so it can make the optimal call given the surrounding code. For example, when there are several valid arguments for a function call, it reasons about which one is most likely the user’s actual intent. The 7B model is then rewarded for matching the judge’s ranking.
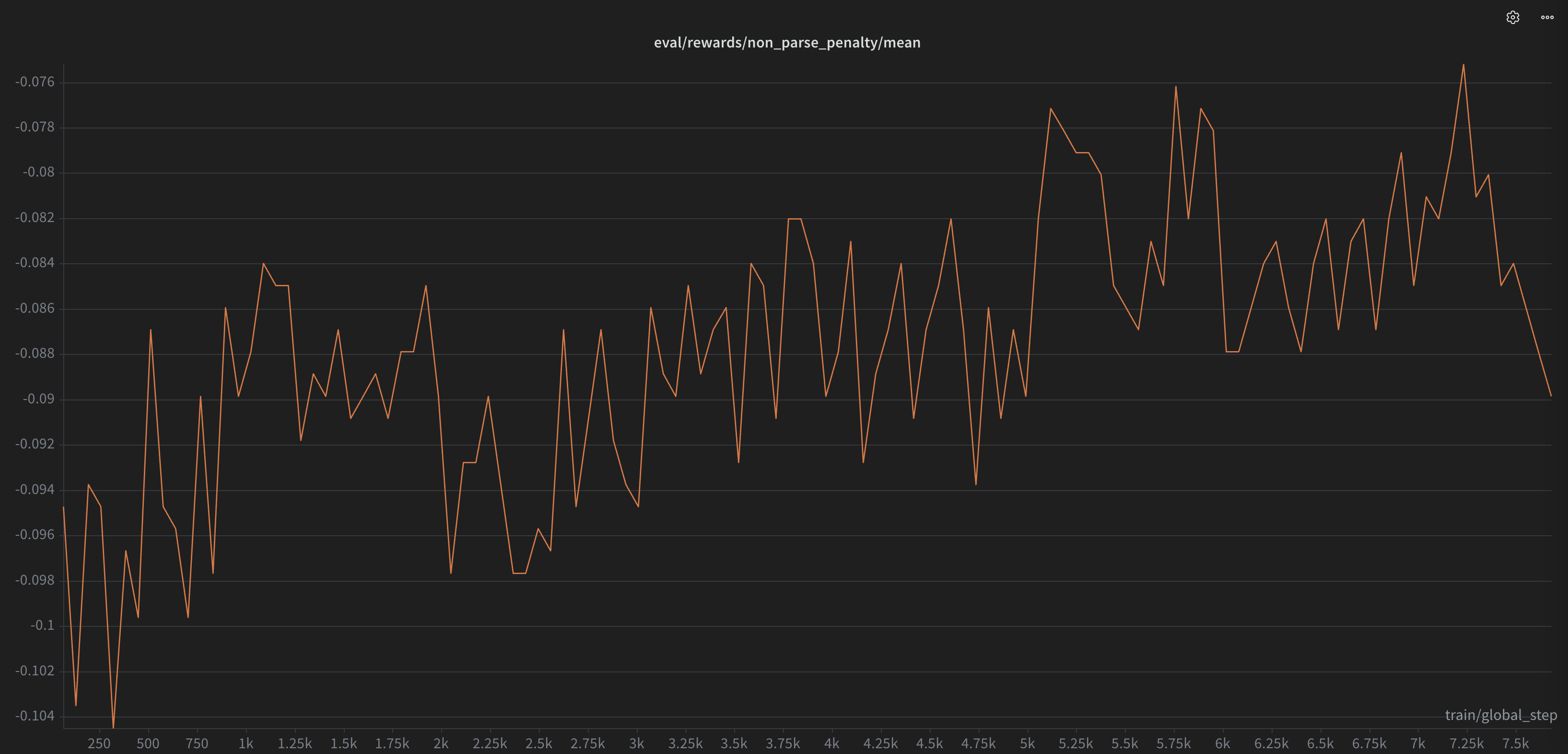
Parse penalty
If applying a completion yields code that doesn’t parse, we penalize it — the same idea as in our previous RL pipeline. It’s a cheap, deterministic signal that keeps the model from breaking the file.
Preference aligning with real users
We trained this run with Claude Opus 4.5 as the judge, around autumn 2025. At that point even strong models had a tendency to write overly fail-safe code — reaching for dict.get(key) instead of dict[key], or wrapping things in defensive checks the developer never asked for. It was one of the most common sources of user frustration.
To fix it, we preference-aligned the model against what users actually do. We record the developer’s edits for ~30 seconds after a suggestion is shown and use that real behavior as the preference signal — rewarding completions that match what the user kept, penalizing the ones they rewrote. This improved our acceptance rate by ~2%, with a lot of users telling us the new autocomplete “just gets me.”
The runtime
Serving a next-edit model quickly is as much an inference problem as a modeling one, so we’re also open sourcing our fork of TensorRT-LLM. It includes the n-gram speculative decoding and early-cancellation work we built to get autocompletes under 100ms.
We built this fork back in May 2025, before n-gram speculative decoding had landed in NVIDIA’s upstream TensorRT-LLM. It’s since been added upstream — but only for the PyTorch runtime, which for our Qwen2.5-based model is 2-3x slower than the TensorRT-LLM runtime. So our fork is still the fastest way to serve these models, and we’re sharing it so others don’t have to reimplement the same optimizations.
Try it out
Both the model and the runtime are open source under permissive licenses. Grab them, build them into the editor of your choice, and let us know what you make — contributions are welcome.